As a Computational Design Summer Associate on the Sidewalk Labs Generative Design team, I focused on scaling the utility of urban prototyping tools by automating the integration of complex spatial datasets.
My work addressed a critical bottleneck: the friction involved in importing and transforming geospatial data for use in generative design objective functions. I conducted foundational research to identify high-impact use cases and the specific standardized datasets—such as pedestrian activity and transit accessibility—required to enhance the accuracy of spatial analyses.
The final result was the development of a replicable, automated pipeline for the ingestion and analysis of urban spatial data. By streamlining this workflow, I enabled the generative design tool to move beyond narrow test cases, allowing for more diverse, data-rich urban simulations that directly inform the optimization of city-scale prototypes.
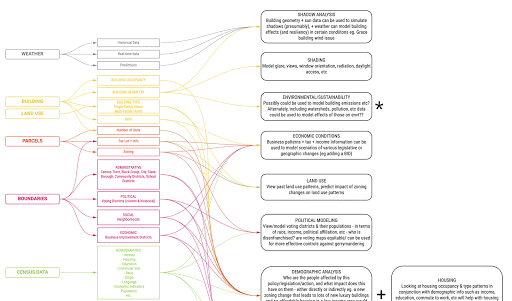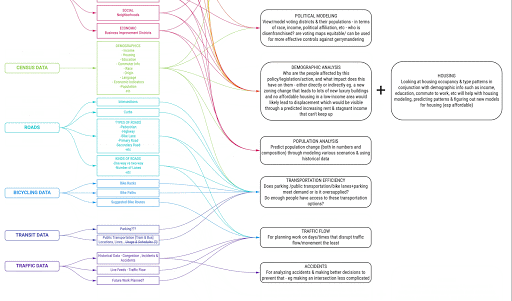
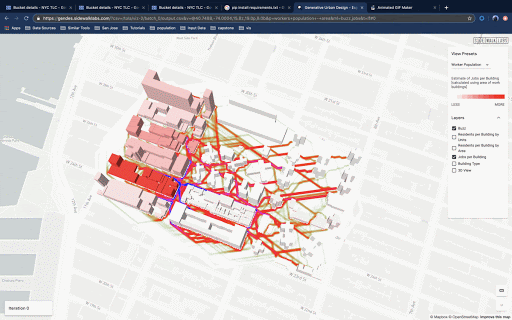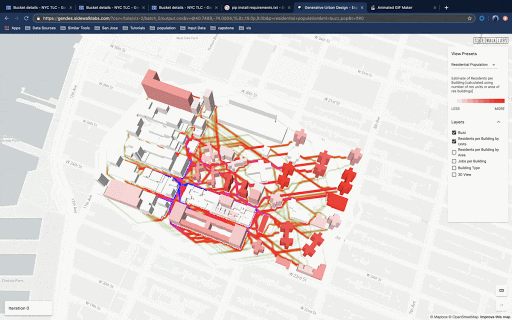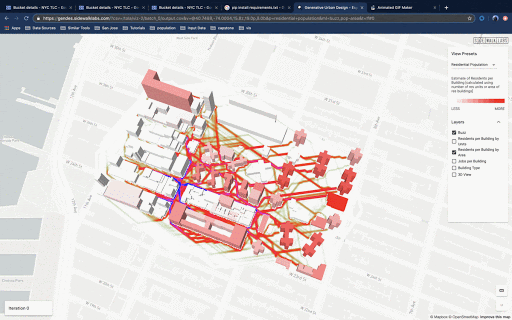
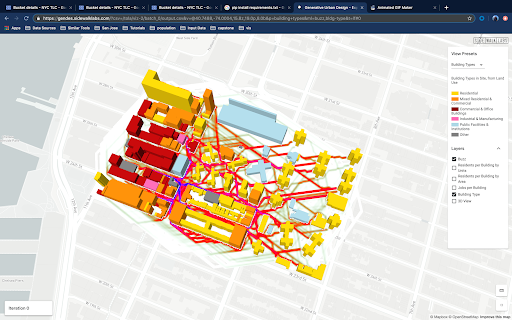
The ingestion of spatial data into the pipeline was streamlined through a series of automated processes. A disaggregation of the resident and workforce population datasets from larger census geographies into buildings was also used to estimate pedestrian activity at the street level. This process was conducted using a test site, but validated through replication in other cities and over a larger area.
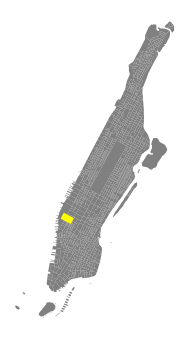
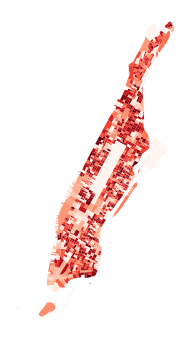
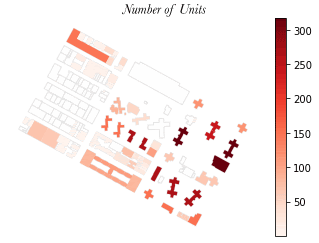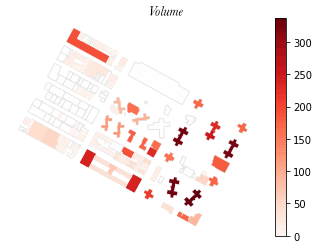
This process could be integrated into the existing generative design workflow to generate building-level population, workforce and land use among other data as well as a 'buzz metric', which visualizes pedestrian activity.